












プロンプトはもう“職人芸”じゃない:再現性を上げるテンプレ設計術
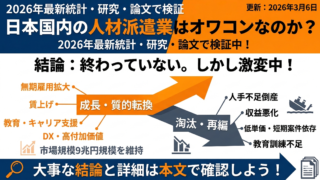
2026年4月12日時点で確認できる公開情報を踏まえると、プロンプト設計の主戦場は「センスの良い一発芸」から、「再利用できるテンプレ」「評価できる入出力」「更新履歴を追える運用」へかなり明確に移っています。 ここ1年ほどで、主要ベンダーの公式ガイドはそろって、テンプレ化、スキーマ化、評価、自動化、バージョン管理を前提にした設計へ重心を移しました。つまり、よいプロンプトは“うまい言い回し”ではなく、再現可能な設計資産として扱うべき段階に入っています。
本稿では、この変化を「最新動向」「実務上の設計原則」「関連研究から見える示唆」の3層で整理します。結論を先に書けば、再現性を上げる鍵は、役割を固定したテンプレ、明示的な構造、評価セット、バージョン管理、そして必要に応じた自動最適化です。
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/52d5546c.1d5dcb6f.52d5546d.353e37f8/?me_id=1400231&item_id=10001200&pc=https%3A%2F%2Fimage.rakuten.co.jp%2Fugreen-gear%2Fcabinet%2Fbiiino%2Fitem%2Fmain-image-2%2F20250314182744_7.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
1. 最新動向:プロンプトは“文章”ではなく“運用単位”になった
1-1. テンプレとバージョン管理が公式機能になっている
OpenAI の現行ドキュメントでは、プロンプトは単発のテキストではなく、versioning と templating を備えた long-lived prompt objectとして扱われています。これは実務上かなり大きな変化です。従来は、優秀な担当者がメモ帳やコード内に埋め込んだプロンプトを属人的に運用しがちでした。しかし現在は、テンプレを共有資産として管理し、変数を差し替え、評価で比較し、バージョン単位で改善するという発想が公式に推奨されています。
この流れは、「プロンプトエンジニアリング」という言葉の重心が、文才や勘所から、設定ファイル的な設計・検証・保守へ移ったことを意味します。実務では、プロンプトはもはやコピーの技巧ではなく、API・ツール・テストと結びついた設定資産です。
1-2. “何を出してほしいか”だけでなく、“どういう形で出すか”が重視される
近年の公式ガイドで目立つのは、Structured Outputs や JSON schema の活用です。OpenAI の資料では、構造化出力は一貫したフォーマットを得る基本手段として扱われ、Office/PDF 系の抽出でも「常に schema か JSON shape を与える」ことが推奨されています。これは、テンプレ設計の焦点が、単なる指示文の洗練から、入出力の契約を固定する設計へ移ったことを示します。
再現性の観点では、この変化は本質的です。なぜなら、モデルの出力ブレは、言い回し以前に期待フォーマットの曖昧さから生じることが多いからです。テンプレで役割、入力、制約、出力項目、欠損時の扱いまで固定すると、担当者が変わっても挙動が安定しやすくなります。
1-3. 最新の実務ガイドは「評価セット込み」で設計せよと言っている
2025年の OpenAI Cookbook では、プロンプト改善を感覚で回すのではなく、golden set を使った automated eval suiteで反復する考え方が明確に打ち出されています。ここで重要なのは、「プロンプトの良し悪し」は会議室の主観ではなく、固定データに対してどの程度一貫して目的を満たすかで測るべきだという点です。
つまり現在の実務では、良いテンプレとは、書いて終わりの文面ではありません。テンプレ本体、差し込み変数、入出力スキーマ、評価データ、観測ログまで揃ってはじめて、改善可能なプロンプトになります。
2. 研究・論文から見えること
2-1. 手作業最適化から、自動探索・コンパイルへ移っている
関連研究では、すでに「人間がひたすら文面を書き換える」段階を越えています。EMNLP 2023 の Automatic Prompt Optimization with "Gradient Descent" and Beam Search は、プロンプト改善を探索問題として扱いました。2023年の Promptbreeder は、プロンプトを進化的に変異・選抜する考え方を提示しました。さらに DSPy は、自然言語の指示そのものを手で詰めるのではなく、宣言的に LM パイプラインを書き、それをコンパイル・最適化する方向を打ち出しています。
ここから読み取れるのは、優れた実務が「匠の言い回し」から「探索可能なテンプレ部品」へ移っていることです。プロンプトは文章であると同時に、探索・差し替え・評価が可能なパラメータ空間として理解され始めています。
2-2. ただし“自動最適化なら何でも勝てる”わけではない
一方で、2024年の Are Large Language Models Good Prompt Optimizers? や Revisiting OPRO: The Limitations of Small-Scale LLMs as Optimizers などは、LLM 自身を最適化器として使う手法に限界があることも示しました。これは実務的にも重要です。自動探索は有力ですが、目的関数が曖昧で、評価データが弱く、採点方法が不安定な状態では、改善が見かけ倒しになりやすいからです。
要するに、自動最適化の価値は「プロンプトを自動で書いてくれること」ではありません。むしろ、テンプレの比較を定量化し、どこが効いているのかを反復可能にすることにあります。再現性を求めるなら、まず評価軸を固め、その上で探索を使う順番が筋です。
2-3. “構造を分ける”こと自体が性能改善に寄与する
Anthropic の公式ガイドは、複数コンポーネントを含むプロンプトでは XML タグで <instructions>、<example>、<formatting> などを分離する方法を推奨しています。これは単なる読みやすさの問題ではありません。命令、文脈、例、出力形式を分離すると、モデルが役割を取り違えにくくなるためです。
この考え方は多くの失敗例とも整合します。プロンプトが不安定になる典型例は、条件、例示、禁止事項、出力形式が一塊になり、どこまでが命令でどこからが参考例かをモデルが曖昧に解釈するケースです。テンプレ設計術の核心は、文面を上手に書くことではなく、意味の境界をはっきり切ることです。
3. 再現性を上げるテンプレ設計の実務原則
3-1. テンプレを5ブロックに分ける
実務では、次の5ブロックでテンプレを固定すると運用しやすくなります。
- Role: モデルの役割と優先順位。例: 「編集者として、まず事実整合性、その次に簡潔さを優先する」。
- Input Contract: 入力の前提、与えられる変数、入力欠損時の扱い。
- Procedure: 実行手順。必要なら段階を箇条書きで固定する。
- Output Contract: JSON schema、見出し構成、必須項目、禁止表現。
- Examples / Edge Cases: 代表例と失敗しやすい境界条件。
この形にすると、変えるべき箇所と変えてはいけない箇所が分離されます。結果として、改善作業が「全部を書き直す」ではなく、どのブロックの修正が効いたのかを追跡できる更新になります。
3-2. 可変部分は“変数”として扱う
再現性を落とす原因の一つは、担当者ごとに微妙に文面を変えてしまうことです。したがって、案件名、読者層、禁止事項、長さ制約、言語、参照資料などは、テンプレ本文に直接打ち込まず、変数として明示的に差し込むほうがよいです。これにより、差分は「設計変更」ではなく「入力差分」として管理できます。
3-3. 出力は“自然文”ではなく“契約”として定義する
もし業務フローの後段に、人間レビュー、DB 格納、CMS 投稿、別エージェントへの受け渡しがあるなら、出力を自然文の雰囲気に任せるべきではありません。必須キー、列挙値、空欄時の値、引用 URL の形式まで固定し、後工程が機械的に扱える契約にします。ここでいうテンプレ設計術は、ライティング術よりも、むしろインターフェース設計です。
3-4. “良い例”だけでなく“悪い例”も入れる
few-shot の例を入れる場合、多くのチームは良い出力例だけを置きます。しかし再現性を高めるなら、避けたい誤答や逸脱例を短く示すのが有効です。禁止事項を抽象語で書くより、具体的に「この出力は不可」と示したほうが、境界条件が安定しやすくなります。
3-5. テンプレの更新は必ずログとセットで行う
更新履歴が残らないプロンプトは、最終的に必ず属人化します。最低限、変更日、変更理由、期待した改善点、評価結果を残す運用が必要です。OpenAI の prompt object のようにバージョン前提の仕組みが出てきたのは、この要請が現場レベルで共通化してきたからだと解釈できます。
4. 現場で使える簡易テンプレ
<role>
あなたは {job_role} です。
優先順位は {priority_1} > {priority_2} > {priority_3} です。
</role>
<input_contract>
入力は {input_type} です。
不足情報がある場合は推測で補わず、{fallback_rule} に従ってください。
対象読者は {audience} です。
</input_contract>
<procedure>
1. 入力を要約する
2. 判断に必要な論点を列挙する
3. 制約に照らして出力を作る
4. 最後に禁止事項違反がないか確認する
</procedure>
<output_contract>
出力は {format} で返してください。
必須項目は {required_fields} です。
不明な項目は null と明記してください。
</output_contract>
<bad_output_examples>
- 根拠のない断定
- 指定外フォーマット
- 入力にない事実の補完
</bad_output_examples>
この程度まで骨格を固定するだけでも、同じタスクを別日に回したときのブレはかなり減ります。重要なのは、美しい文章を書くことではなく、判断の入り口と出口を固定することです。
5. 2026年時点の示唆
- プロンプト単体最適化の時代は終わりつつある: 現在は、テンプレ、ツール呼び出し、スキーマ、評価、ログを含むシステム設計が中心です。
- 再現性の単位は“文章”ではなく“テンプレ + eval”: 同じ入力でどれだけ安定して目的を満たすかが重要です。
- 人手の勘はまだ必要だが、置く場所が変わった: 文面の職人芸よりも、どの変数を切り出し、何を測り、どこを固定するかの設計判断が重要です。
- 自動最適化は補助輪であって免罪符ではない: 評価系が弱いと、探索結果の改善は簡単に錯覚になります。
6. まとめ
「プロンプトは職人芸か」という問いに対する、2026年4月12日時点の実務的な答えはかなり明快です。優れたプロンプトは依然として設計センスを要するが、運用の中心はすでにテンプレ化・構造化・評価・バージョン管理へ移っている、です。
したがって、再現性を上げたい組織がやるべきことは、プロンプトの名人を探すことではありません。テンプレを部品化し、変数を明示し、出力契約を固定し、評価セットで更新を比較できる仕組みを持つことです。プロンプト設計術は、もはや言葉選びの芸ではなく、ソフトウェア設計に近い営みになっています。
参考情報
- OpenAI Docs: Prompting – Prompts in the API
- OpenAI Cookbook: Practical Guide for Model Selection for Real-World Use Cases
- OpenAI Cookbook: GPT-5.2 Prompting Guide
- Anthropic Docs: Use XML tags to structure your prompts
- Promptbreeder: Self-Referential Self-Improvement via Prompt Evolution
- DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
- Automatic Prompt Optimization with "Gradient Descent" and Beam Search
- Are Large Language Models Good Prompt Optimizers?
- Revisiting OPRO: The Limitations of Small-Scale LLMs as Optimizers


コメント