










AIによる言語習得プロセスの書き換え最前線 2026年3月時点で見る最新研究・論文・実装潮流
2026年3月21日時点で公開情報を確認すると、AIによる言語習得研究の焦点は、単に「大量テキストを次単語予測で学習させる」方式から大きく移りつつある。いま最前線で起きているのは、少量データ、発達段階に沿ったカリキュラム、教師からの相互作用的フィードバック、画像や世界知識による接地、計算量制約の下での人間らしさ評価を組み合わせ、子どもの言語獲得により近い学習条件を機械側へ持ち込もうとする流れである。言い換えれば、AIは言語を「大量に読む」だけではなく、段階的に教えられ、問い返し、試し、修正し、文脈に接地しながら学ぶ方向へ再設計され始めた。
要点
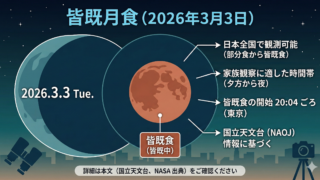
- 2024年11月の第2回 BabyLM Challenge では、100M語以下という制約下で、データ選定・学習目標・アーキテクチャ設計の工夫が性能差を大きく左右した。
- 2025年11月の First BabyLM Workshop では、interaction track が導入され、教師モデルからのフィードバックを受けながら学ぶ設定が正式に競技化された。
- 2025年4月の NAACL 論文「Babysit A Language Model From Scratch」は、試行と教師デモンストレーションの組み合わせが単語獲得を加速すると示した。
- 2025年 ACL 論文「INTERACT」は、質問駆動型の相互学習が広いタスク群で性能を押し上げ、条件によっては最大25%の改善を報告した。
- 最新動向の本質は、言語習得を静的コーパス最適化から、発達的・対話的・接地的プロセスへ書き換えることにある。
1. なぜ「言語習得プロセスの書き換え」が起きているのか
従来の大規模言語モデルは、巨大コーパスを一方向に読み込んで統計的規則を圧縮することで性能を上げてきた。しかし人間の子どもは、そこまで大量の入力を必要としない。BabyLM 系列の研究は、このギャップを明確な問題として扱い、人間は少量入力・社会的相互作用・世界接地を通じて効率的に言語を学ぶのに、なぜAIは膨大なテキストを必要とするのかを問うてきた。2024年から2025年にかけて、この問いは共有タスク、ワークショップ、対話型学習論文として急速に制度化され、単なる認知科学的比喩ではなく、具体的なモデル設計原理へ変わっている。
2. 2024年の基準点: BabyLM Challenge が示したもの
2024年11月公開の「Findings of the Second BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora」は、この分野の基準点である。同チャレンジでは 10M 語・100M 語・100M語+画像の各トラックが用意され、31件の提出が比較された。結果として、ハイブリッドな causal-masked 言語モデルが有力であり、訓練 FLOPs と平均性能に強い相関があり、さらに上位手法は単純なモデル大型化ではなく、訓練データの組成、訓練目標、アーキテクチャを同時に最適化していたことが示された。一方で、マルチモーダル・トラックではベースライン超えが達成されず、画像接地を本当に効かせる難しさも露呈した。
この結果は重要である。なぜなら、最新の研究潮流が「接地は重要だ」と主張するだけでなく、現状のAIは接地をうまく使いこなせていないことを、共有タスクレベルで可視化したからである。2026年3月時点で見ても、ここはまだ解決済みではなく、今後の競争軸として残っている。
3. 2024年に見えた設計原理: データ選定、語彙縮小、発達カリキュラム
同じく 2024年11月の Ghanizadeh と Dousti による「Towards Data-Efficient Language Models: A Child-Inspired Approach to Language Learning」は、少量データ設定で何が効くかを比較的素直に示している。この研究では、10M語トラックの訓練データを子ども向け発話中心に再構成し、語彙サイズを 32,000 に抑え、カリキュラム学習を導入した。結論は明快で、子どもに近い入力分布へ寄せること、語彙を無制限に広げないこと、段階的に学ばせることが有効であり、逆に一般的な大規模Webコーパスを混ぜると性能が悪化するケースも確認された。
さらに Lucas らの「Using Curriculum Masking Based on Child Language Development to Train a Large Language Model with Limited Training Data」では、幼児発達の時間軸に合わせて、最初は単純な名詞から、徐々により複雑な品詞や構造へ広げる curriculum masking が検討された。ここでも示唆は一貫している。何を、どの順番で、どれくらい抽象度を上げながら学ばせるかが、言語習得効率の中核にあるということだ。
4. アーキテクチャ面の書き換え: Transformer 一強ではなくなってきた
2024年の BabyHGRN 論文は、低資源言語モデル設定で HGRN2 系の再帰的アーキテクチャが Transformer 系ベースラインを上回る結果を報告した。これは、言語習得の効率化が単に学習レシピの問題ではなく、どの計算構造が限られた入力から規則性を取り出しやすいかの問題でもあることを示している。2025年 BabyLM Workshop でも、hybrid pretraining、morpheme-aware 設計、単層小型モデル、LoRA を使った制約下学習など、多様な方向性が並んだ。つまり最新潮流は、「大きい Transformer を少し工夫する」から、「人間らしい制約下で有利な構造を探す」へと広がっている。
5. 2025年の決定的転換: 相互作用が正式な学習メカニズムになった
2025年11月の First BabyLM Workshop の報告で最も重要なのは、interaction track の導入である。ここでは student model が larger teacher model からフィードバックを受けながら学ぶことが許可され、新たに人間らしさを測る認知・言語評価や、中間チェックポイント評価、計算量制約も導入された。これは象徴的な変化であり、AIの言語習得を「静的事前学習」から「教えられながら育つプロセス」へ制度的に押し進めた。
2025年4月 NAACL の「Babysit A Language Model From Scratch: Interactive Language Learning by Trials and Demonstrations」は、この流れを代表する論文である。著者らは TnD(trial-and-demonstration)学習を提案し、学生モデルが試行し、教師がデモを与え、段階別報酬を受ける枠組みを検証した。結果として、教師のデモと学習者自身の試行の両方が単語獲得を速めること、試行頻度が学習曲線に強く関係することが示された。これは、人間の言語発達で重視されてきた「自分で使ってみる」「相手に直される」が、AIでも機能することを示す直接的な証拠である。
同年11月の *SEM 2025 論文「Modeling Language Learning in Corrective Feedback Interactions」も、教師が reformulation を与える相互作用型フレームワークを提示し、文法的・意味的に正しい発話生成や概念知覚への影響を検証している。ここでの重要点は、最新研究が単に RLHF の延長として相互作用を扱っているのではなく、言語獲得そのものの基本単位として corrective feedback を再評価している点にある。
6. 質問するAIへ: 受動学習から能動学習への移行
2025年 ACL の「INTERACT: Enabling Interactive, Question-Driven Learning in Large Language Models」は、さらに一歩進んでいる。この研究では、student LLM が teacher LLM に対して反復的に質問しながら知識を獲得する。対象はニュース、映画、論文、画像など 1,347 コンテキストに及び、結果として広い条件で性能向上が観測され、条件によっては最大 25% の改善が報告された。しかも cold-start の学生モデルが、わずか数ターンで静的学習ベースラインに追いつくケースもあった。
ここで起きている書き換えは決定的だ。従来のLMは「与えられたものを吸収する装置」だったが、最新研究はAIを質問し、穴を発見し、教師との対話で知識を補完する学習主体として扱い始めている。これは教育工学・認知科学で言うメタ認知や自己説明に近い方向であり、2026年以降のエージェント型学習へ直結する可能性が高い。
7. 接地の課題: 画像や世界経験はまだ十分には統合されていない
最新動向を過度に楽観視すべきではない。2024年の BabyLM Challenge ではマルチモーダル・トラックでベースライン超えが実現せず、接地の難しさがそのまま残った。2025年には grounding 系研究が進み、画像・文化知識・世界情報を組み込む試みは前進したが、言語の意味を視覚や行為に結びつけることは、依然として静的テキスト学習より難しい。つまり、AIによる言語習得プロセスの書き換えは進んでいるが、真に「世界の中で意味を学ぶ」段階まではまだ途上にある。
8. 実務的に何が変わるのか
この流れは、今後のモデル開発とプロダクト設計に直接影響する。第一に、モデル訓練は今後ますますデータ量の拡大競争ではなく、学習順序・フィードバック設計・評価設計の競争になる。第二に、教育AI、対話エージェント、社内ナレッジボットでは、静的 fine-tuning よりも、利用中に問い返して学ぶ interactive learning ループが重要になる。第三に、推論能力や語用論能力の改善には、単なる事前学習コーパス増量より、発達的制約と相互作用をどう組み込むかが効きやすくなる可能性がある。
実際、2025年の BabyLM Workshop が人間らしさ評価や中間チェックポイントを重視し始めたことは、研究評価軸そのものが変わりつつある証拠である。最終精度だけでなく、どの順に何を獲得したか、途中で忘れたか、フィードバックにどう適応したかが評価対象になり始めた。
9. 2026年3月時点での結論
2026年3月21日時点で確認できた最新の公開研究を総合すると、AIによる言語習得プロセスの書き換えはすでに始まっている。ただし、その本質は「LLMが人間のように話せるようになった」という表面的な話ではない。より正確には、AI研究が、言語を学ぶとは何かという設計思想そのものを、静的・一括・大量入力型から、段階的・対話的・接地的・計算制約付きのプロセスへ移し始めたということだ。2024年はその問題設定が共有タスクとして固まり、2025年は相互作用トラックと質問駆動学習が前面に出た。2026年以降の競争は、この流れをどこまで現実のモデル訓練に実装できるかに移るだろう。
要するに、最新研究が示しているのは「AIが人間の言語を模倣する方法」が変わったというより、AIが言語を学ぶための時間軸・教師関係・世界との接続方法が再定義されつつあるという事実である。これこそが、いま起きている「AIによる言語習得プロセスの書き換え」の核心である。
参考文献・参照ソース
- Hu, M. Y. et al. (2024). Findings of the Second BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora.
- Ghanizadeh, M. A. & Dousti, M. J. (2024). Towards Data-Efficient Language Models: A Child-Inspired Approach to Language Learning.
- Lucas, E. et al. (2024). Using Curriculum Masking Based on Child Language Development to Train a Large Language Model with Limited Training Data.
- Haller, P. et al. (2024). BabyHGRN: Exploring RNNs for Sample-Efficient Language Modeling.
- Ma, Z., Wang, Z. & Chai, J. (2025). Babysit A Language Model From Scratch: Interactive Language Learning by Trials and Demonstrations.
- Kendapadi, A. et al. (2025). INTERACT: Enabling Interactive, Question-Driven Learning in Large Language Models.
- Castro-Garcia, J. L. & Kordjamshidi, P. (2025). Modeling Language Learning in Corrective Feedback Interactions.
- Proceedings of the First BabyLM Workshop (2025).
- Fysikoudi, E. et al. (2025). Active Curriculum Language Modeling over a Hybrid Pre-training Method.
- Bölücü, N. & Can, B. (2025). A Morpheme-Aware Child-Inspired Language Model.
注記: 本記事は 2026年3月21日時点で確認できた公開情報をもとに構成した。2026年時点の最新のまとまった学術動向としては、2025年11月の First BabyLM Workshop と、2025年の ACL / NAACL / *SEM 論文群が中心である。今後の査読版・追試・次回共有タスク結果により評価は更新されうる。


コメント