











PythonでMCPサーバを作る最新実装ガイド 2026
Model Context Protocol(MCP)は、LLMアプリケーションと外部ツール・データソースを標準化された形で接続するためのオープンプロトコルです。2026年4月時点では、PythonでMCPサーバを作る実務は「まずFastMCPベースで素早く公開し、必要に応じて認可・HTTP輸送・監査ログ・セッション制御を段階的に加える」という流れが最も現実的です。本稿では、MCP公式仕様、公式Python SDK、最近の仕様改訂、関連研究を踏まえて、いま何を選ぶべきかを整理します。
最新の全体像
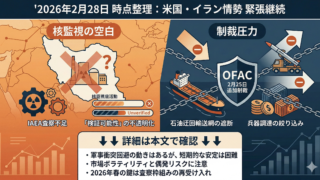
公式仕様では、MCPはJSON-RPC 2.0を基盤とし、resources、prompts、toolsを中心にクライアントとサーバが能力交渉しながら接続します。2026年4月時点で確認できる仕様ページでは、HTTP系の認可枠組み、アイコンメタデータ、セッション管理、Streamable HTTPなど、単なる「CLI向けのstdio連携」よりも一段広い運用前提が明確になっています。つまり、MCPサーバはもはやローカル開発補助だけでなく、組織内ツール連携やWeb配備も想定した設計対象になっています。
Python実装の実務面では、公式Python SDKがTier 1 SDKとして位置付けられており、FastMCPスタイルで短く書ける点が最大の利点です。一方で、2026年4月時点の公式GitHub情報では、mainブランチのv2はまだpre-alpha、本番用途ではv1.xが推奨と明記されています。このため、最新情報を追うべき対象と、本番で採るべき安定版は分けて考える必要があります。
いま選ぶべき実装戦略
現時点の現実解は次の通りです。
- ローカル連携や社内PoCなら
stdioを先に採用する - Webアプリや多クライアント接続を見据えるなら
streamable-httpを初期段階から検討する - Python SDKは安定性重視なら
v1.x系、将来互換の調査はv2ドキュメントで追う - 最初から「toolを増やす」より、「resourceの粒度」「認可」「監査」を先に設計する
特に2025年以降の仕様・SDK文書を見ると、Streamable HTTPは単なる代替輸送ではなく、JSONレスポンス運用、SSE通知、セッション継続性まで含めて、今後の標準HTTP実装の中心に寄っています。ブラウザやSaaSと接続する可能性がある場合、後から輸送層を作り直すより、最初からHTTP前提の境界設計をしておく方が安全です。
最小構成のPythonサーバ例
公式Python SDKの方向性に沿うと、最小構成は次のようになります。
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Docs Search", json_response=True)
@mcp.tool()
def search_docs(query: str) -> str:
return f"query={query}"
@mcp.resource("docs://policy")
def policy() -> str:
return "社内ポリシー本文"
@mcp.prompt()
def summarize_prompt(topic: str) -> str:
return f"{topic} を要約してください。"
if __name__ == "__main__":
mcp.run(transport="streamable-http")この設計で重要なのは、toolは副作用を持つ操作、resourceは参照対象、promptは再利用可能な指示テンプレートとして役割を分けることです。雑に全部toolへ寄せると、クライアント側の権限制御とUI表示が不明瞭になります。
実装時の設計論点
1. toolを細かくし過ぎない
MCPではtool記述がそのままユーザー承認やクライアントUIに影響します。たとえば write_file、delete_file、run_command をむやみに露出すると、モデル能力より前に承認負荷とリスクが増えます。実務では「検索」「取得」「ドラフト作成」「登録」など、監査しやすい業務単位へ寄せるのが無難です。
2. stdioではstdout汚染を避ける
公式クイックスタートが強調している通り、stdioサーバで標準出力に余計なログを書くとJSON-RPCメッセージが壊れます。Pythonでも print() の使い方は厳密に管理し、運用ログはstderrまたはファイルへ逃がすのが基本です。
3. HTTPでは認可設計を後回しにしない
最近の仕様ページでは、HTTPベース輸送には認可フレームワークの考え方が明示されています。社内SSOやトークン検証を後付けすると、resource単位の可視性制御や監査主体の識別が破綻しやすいため、最初に「誰が」「どのtoolを」「どのデータ境界で」使えるのかを確定しておくべきです。
最新動向
FastMCP中心の開発体験が定着
PythonではFastMCP系の記法がそのまま事実上の標準になっています。学習コストが低く、ツール・リソース・プロンプトを少量コードで公開できるため、PoCから導入しやすいのが理由です。
本番はv1.x、先行検証はv2という二層化
2026年4月時点の公式GitHubでは、v2は開発中でpre-alpha、安定版はv1.xです。これは重要です。最新記事やサンプルだけ見るとv2相当の設計が先行して見えますが、本番環境で無条件に追従するのは危険です。特に社内基盤やB2Bプロダクトでは、まずv1.xで安定運用しつつ、v2移行差分を検証環境で吸収するのが妥当です。
stdioからStreamable HTTPへの重心移動
以前はデスクトップアプリ連携の都合でstdio中心の印象が強かったものの、現在の仕様文書とSDK文書ではStreamable HTTPの位置付けがかなり強くなっています。複数クライアント、長寿命セッション、通知、再接続、サーバ配備を考えると、この流れはほぼ不可逆です。
研究と論文から見た示唆
MCPそのものを正面から扱う査読論文はまだ厚くありませんが、周辺研究は実装判断に直結します。
- Instruction Hierarchy(OpenAI, 2024)は、システム指示・ユーザー入力・外部ツール出力の優先順位を学習させる重要性を示しました。MCPサーバ運用では、tool出力やresource内容を無条件に信用しない設計が必要だという示唆になります。
- INFERCEPT(ICML 2024)は、ツール呼び出しで中断されるLLM推論の計算効率問題を扱い、外部ツール統合が単なるアプリ層の話ではなく、推論基盤全体の性能設計に影響することを示しました。サーバ側で応答時間やツール粒度を詰める価値は大きいです。
- 近年のエージェント安全性研究は、ツール出力に埋め込まれた敵対的指示、権限昇格、過剰自動化の危険を繰り返し示しています。MCP公式仕様でも、tool説明やannotationを信頼済みとみなしてはならないと明記されており、研究動向と仕様が一致しています。
実務で外しにくい構成
- まずはFastMCPで1つのresource、1つのread-only tool、1つのpromptだけを公開する
- stdioでInspectorまたは対応クライアントと疎通確認する
- 副作用のあるtoolは承認UIと監査ログを前提に追加する
- HTTP配備時は認証、レート制限、テナント境界、セッション寿命を明示する
- v2の追従は別ブランチで検証し、v1.x本番系と分離する
結論
PythonでMCPサーバを作る方法自体は、2026年時点ではかなり簡潔になりました。しかし難所はコード量ではなく、どの能力を公開するか、どの輸送を使うか、どこで認可と監査を掛けるかにあります。最新動向を踏まえると、短期的にはFastMCP + v1.x安定運用、中期的にはStreamable HTTPと認可設計、長期的にはv2移行とエージェント安全性対策が主戦場です。単に「動くサーバ」を作るより、「安全に運用できるMCPサーバ」を最初から設計することが、今のベストプラクティスです。


コメント