










公開時点: 2026年4月2日時点
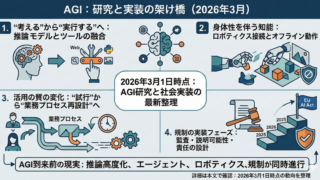
生成AIの中心がテキストや画像の理解・生成から、現実世界で見て、考え、動く段階へ移った。いま起きているのは、単なるロボット制御の高度化ではない。大規模モデルが、視覚・言語・行動・シミュレーションを横断して統合され、AIが「画面の中の知能」から「身体を通じて世界に作用する知能」へ変わり始めたことに本質がある。
この流れを象徴するキーワードは4つある。Vision-Language-Action(VLA)、世界モデル / World Foundation Models、オンデバイス化、そして全身制御だ。2025年から2026年初頭にかけて、Google DeepMind、NVIDIA、Figure AIなどが出した技術発表と文書を並べると、「身体を持つAI」が研究テーマから産業実装フェーズへ入り始めたことがはっきり見える。
1. 何が変わったのか: AIは“理解”だけでなく“作用”を学び始めた
従来の大規模モデルは、質問応答、要約、コード生成、画像生成のように、基本的にはデジタル空間で完結する能力が中心だった。これに対して身体性AIでは、モデルは次の循環を扱わなければならない。
- カメラやセンサーから環境を観測する
- 言語指示をタスクへ変換する
- 物体・空間・他者の状態を予測する
- 手先・腕・胴体・脚を連続制御する
- 失敗や外乱を受けて再計画する
つまり、身体を持つAIの核心は、推論を行動へ落とし込むレイテンシ、頑健性、汎化性能にある。2025年以降の進展は、この難所が個別技術ではなく、基盤モデル群として束ねられ始めた点にある。
2. 最新動向タイムライン: 2025年から2026年初頭まで
|
日付 |
主体 |
発表 / 文書 |
意味 |
|---|---|---|---|
|
2025年1月6日 |
NVIDIA |
Cosmos World Foundation Model Platform / Cosmos論文 |
物理AI向けの世界モデルを、学習基盤と合成データ基盤として体系化した。 |
|
2025年2月20日 |
Figure AI |
Helix |
視覚・言語・行動を一体化し、ヒューマノイド上半身を高頻度制御するVLAを提示した。 |
|
2025年3月18日 |
NVIDIA |
Isaac GR00T N1 / GTC発表 |
ヒューマノイド向けオープン基盤モデルと合成データ生成フレームを前面化した。 |
|
2025年3月25日 |
Google DeepMind |
Gemini Robotics: Bringing AI into the Physical World |
Gemini 2.0系を身体化し、Embodied Reasoning と高頻度制御を接続した。 |
|
2025年6月24日 |
Google DeepMind |
Gemini Robotics On-Device |
ロボット本体上で動く低遅延VLAへの移行を示した。 |
|
2025年9月29日 |
NVIDIA |
World Simulation With Video Foundation Models for Physical AI |
世界シミュレーションの長尺化・多視点化が進み、学習前段のデータ生成がさらに強化された。 |
|
2026年1月27日 |
Figure AI |
Helix 02 |
上半身中心から、歩行・バランス・操作を含む全身自律へ拡張した。 |
3. 技術トレンド1: VLAが“ロボット版LLM”の位置を占め始めた
2025年の最大の変化は、ロボティクスが個別タスク学習から汎用VLAへ重心を移したことだ。VLAは、画像や動画で環境を見て、自然言語で目的を受け取り、連続値のアクションを出力する。言い換えると、LLMがトークン列を生成するのに対し、VLAは現実世界の行為列を生成する。
Figure AIのHelixは2025年2月20日に、単一のニューラルネットワーク系でヒューマノイドの上半身全体を扱うVLAとして提示された。公開内容では、System 2が7〜9Hzで高水準の理解を担い、System 1が200Hzで反応的な連続制御を担う構成が示されている。これは「遅い推論」と「速い制御」を分離しつつ協調させる設計であり、身体性AIで長く問題だった汎化性能とリアルタイム性の両立に対する実践的回答だ。
Google DeepMindのGemini Robotics On-Deviceも同じ文脈にある。2025年6月24日の発表では、ネットワーク接続に依存しないローカル実行、低遅延、そして新規タスクへの適応を重視し、SDK経由で50〜100件程度のデモから新しいドメインへ調整できることを示した。これは「巨大モデルはクラウドにしか置けない」という前提を崩しつつある。
4. 技術トレンド2: 世界モデルが“訓練前の訓練”を担い始めた
身体を持つAIで最も高価なのは、現実世界でのデータ収集と失敗コストだ。ここで急速に重要性を増したのが、世界モデルまたはWorld Foundation Modelsである。NVIDIAは2025年1月6日にCosmos World Foundation Model Platform for Physical AIを公表し、物理AIには「ポリシーのデジタルツイン」と「世界のデジタルツイン」の両方が必要だと整理した。
重要なのは、世界モデルが単なる映像生成ではなく、物理的にもっともらしい未来状態の予測と、学習用データ生成、エッジケース生成、安全検証を兼ねるインフラになってきたことだ。NVIDIAは同年9月29日のWorld Simulation With Video Foundation Models for Physical AIで、多視点・長尺・制御可能な生成へ進化したことを示しており、ロボットの実機学習の前に、仮想世界で失敗を大量消化する流れが一段と鮮明になった。
この変化は、自然言語AIにおける「事前学習コーパス」に相当するものが、身体性AIでは「シミュレーション可能な世界そのもの」になりつつあることを意味する。今後の差は、モデルの大きさだけでなく、どれだけ多様で物理整合的な世界を生成・評価できるかで決まる可能性が高い。
5. 技術トレンド3: オンデバイス化で“ロボットがその場で考える”段階へ
身体性AIでは、クラウド依存は致命的な弱点になりやすい。ネットワーク遅延、切断、プライバシー、現場環境のばらつきがあるためだ。2025年の後半にかけて注目されたのは、VLAのオンボード実行だった。
Google DeepMindはGemini Robotics On-Deviceで、双腕ロボット向けのローカル実行モデルを提示した。Figure AIのHelixも、低消費電力の組み込みGPU上でS1/S2を分担実行する設計を示している。これは単なる実装上の改善ではなく、AIが「クラウド経由のアシスタント」から「現場に常駐するエージェント」へ移る条件そのものだ。
実運用の観点から見ると、オンデバイス化は次の意味を持つ。
- ミリ秒〜数百ミリ秒単位の応答性が必要な操作に耐えやすい
- 工場、倉庫、家庭など接続が不安定な環境でも使いやすい
- 映像や空間データを外部送信しない設計がしやすい
- 安全停止や再計画をローカルで完結できる
2025年は、身体性AIが“クラウドで賢い”だけでは足りず、ロボット本体で十分に速く賢いことが競争条件になった年だったと言える。
6. 技術トレンド4: 上半身制御から全身自律へ
ヒューマノイドの難しさは、手先の把持だけでは終わらない。歩行中は視点も重心も変わり、脚・胴体・首・腕・指が相互依存する。2026年1月27日にFigure AIが公開したHelix 02は、この壁を越える方向性を強く印象づけた。
同発表では、Helix 02が単一のニューラルシステムで、歩行・操作・バランスを部屋スケールで連続的に扱うと説明されている。これは、ロボットAIの単位が「アーム制御」や「把持スキル」ではなく、身体全体を一つの行為主体として扱うフェーズへ進んだことを意味する。
この方向は、家庭や物流、現場支援のような“移動しながら作業する”環境では決定的に重要だ。AIが身体を持つとは、マニピュレーション能力だけでなく、空間移動・姿勢変化・視点変化込みでタスクを解けることを意味するからだ。
7. 代表的な技術文書・論文
- Cosmos World Foundation Model Platform for Physical AI(NVIDIA, 2025年1月6日)
世界モデルを物理AIの基盤として整理した文書。合成データ、トークナイザ、ポストトレーニングまで含めてプラットフォーム化している点が重要。 - NVIDIA Isaac GR00T N1: An Open Foundation Model for Humanoid Robots(NVIDIA Research, 2025年3月17日公開)
ヒューマノイド向けのオープン基盤モデル。人の動画、実ロボット軌跡、シミュレーション、合成データを束ねる方向性を示した。 - Gemini Robotics: Bringing AI into the Physical World(arXiv:2503.20020, 2025年3月25日)
Gemini 2.0をベースに、Embodied Reasoning と VLA を接続した技術報告。身体性評価や安全評価の枠組みも含む。 - World Simulation With Video Foundation Models for Physical AI(NVIDIA Research, 2025年9月29日)
世界シミュレーションを多視点・長尺・高制御性へ進め、ポストトレーニング前提のデータフライホイールを強化した。
8. いま見えている産業的インパクト
最新動向を総合すると、身体性AIの商用化は、まず単純作業の完全自動化ではなく、変動の大きい半構造化環境から広がる可能性が高い。物流、倉庫、簡易組立、検品、家庭内補助が典型だ。理由は明快で、こうした現場は人手不足が大きく、かつルールベース自動化だけでは変化に追随しづらいからである。
Figure AIが2025年6月7日に公開した物流アップデートでは、Helixが複数の梱包形状に対応し、処理速度やバーコード向きの成功率を改善したとされる。これは「研究デモ」から「業務KPI」へ評価軸が移っていることを示す。身体性AIの次の競争は、ベンチマーク精度だけでなく、1時間あたり処理件数、失敗率、再学習コスト、安全停止率のような運用指標で起きる。
9. まだ残る課題
- 安全性: 物理世界では誤りがそのまま破損や事故になる。ソフトウェアのハルシネーションとは被害の質が違う。
- 長期信頼性: デモでできることと、数千回連続で壊れずにできることは別問題である。
- データ収集の偏り: 家庭・倉庫・工場は環境差が大きく、汎化の難所が多い。
- 評価系の不足: 身体性AIはLLMのように単一スコアで比較しにくく、実機・シミュレーション・安全評価の統合が必要。
- コスト構造: モデルだけでなく、ハードウェア、保守、電力、回収動線まで含めた全体最適が要る。
10. 結論: 「身体を持つAI」は始まったが、勝負はこれから
2025年から2026年初頭までの流れを見ると、身体性AIはもはや概念実証だけの段階ではない。VLAはロボットの共通言語になりつつあり、世界モデルは実機学習を支える前処理インフラになり、オンデバイス化は現場導入の条件になり、全身制御はヒューマノイドの実用ラインを押し上げている。
ただし、本当の意味で「AIが画面を飛び出した」と言えるのは、ロボットが一度できることではなく、多様な現場で、長時間、低コストで、安全に、再現良く働けるようになった時だ。その意味で、2025年は始まりの年であり、2026年以降は“モデルの驚き”ではなく“運用の現実”が問われるフェーズに入る。
それでも流れは明確だ。AIは、読む・書く・描く段階を越えて、見る、触る、運ぶ、歩く段階へ踏み込んだ。身体を持つAIは、もう未来予想図ではなく、現在進行形の技術競争になっている。
出典
- NVIDIA Research: Cosmos World Foundation Model Platform for Physical AI
- NVIDIA Research: NVIDIA Isaac GR00T N1
- arXiv: Gemini Robotics: Bringing AI into the Physical World
- Google DeepMind: Gemini Robotics On-Device
- Figure AI: Helix
- Figure AI: Helix 02
- NVIDIA Research: World Simulation With Video Foundation Models for Physical AI


コメント